Predict the Curve Flattening: Difference between revisions
(→Links) |
|||
| (64 intermediate revisions by the same user not shown) | |||
| Line 1: | Line 1: | ||
__NOTOC__ | |||
[[File:WirVsVirusLogoSmall.png|link=https://wirvsvirushackathon.org/|right]] | |||
<youtube>bhWTAO7oQuo</youtube> | |||
__TOC__ | |||
= Result = | |||
* https://youtu.be/bhWTAO7oQuo | |||
* https://paul-em.github.io/wir-vs-virus/ | |||
* https://devpost.com/software/1757_flattenthecurve_predictivemodeling-tyeo67 | |||
=== Comparable Results === | |||
* https://devpost.com/software/what-can-i-do-changing-my-behavior-changes-the-curve | |||
* https://devpost.com/software/01_008_corona_tracking_predictive_risk_area_modeling | |||
* https://devpost.com/software/038_daten_flatcurver | |||
** <youtube>LJ0YyNdmV9A</youtube> | |||
** https://flatcurver.de/#/ | |||
** https://github.com/CloseChoice/FlatCurver | |||
* https://devpost.com/software/1_044_b_flatten-the-curve_optimize-the-curve | |||
** <youtube>N3yKUk_tfBY</youtube> | |||
** http://covidsim.eu/ | |||
==== COVID-19 Simulation ==== | |||
<youtube>lwUDvNfVeEo</youtube> | |||
=== Johns Hopkins University Data === | |||
* https://github.com/pomber/covid19 | |||
= Slack = | = Slack = | ||
herausforderung_164 is the channel you can ask for an invitation on 1_038_a_daten | herausforderung_164 is the channel you can ask for an invitation on slack channel 1_038_a_daten | ||
Active structured documentation is now at https://docs.google.com/document/d/1DMAisYOtO1RZU7OVzppxrlRGVhjzJNq3eRiKbNHKC-g/edit# | |||
= Organisation = | = Organisation = | ||
== Aufgabe == | == Aufgabe == | ||
| Line 10: | Line 38: | ||
=== Probleme === | === Probleme === | ||
Jeder redet von #flattenthecurve aber wie sieht die Kurve eigentlich aus und wie entwickelt sie sich? Ich habe in den letzten Tagen bereits eine Open-Source Visualisierung mit Daten der John Hopkins University gemacht: https://paul-em.github.io/covid-19-curves/Spannend wäre allerdings zu wissen wie sich anhand des Momentums die Kurve entwicklen könnte und vielleicht noch andere Darstellungsformen zu entwickeln. Vielleicht wären hier Mathematiker ganz gut. Ich wäre als Informatiker jedenfalls dabei! | Jeder redet von [https://twitter.com/search?q=%23FlattenTheCurve #flattenthecurve] aber wie sieht die Kurve eigentlich aus und wie entwickelt sie sich? Ich habe in den letzten Tagen bereits eine Open-Source Visualisierung mit Daten der John Hopkins University gemacht: https://paul-em.github.io/covid-19-curves/Spannend wäre allerdings zu wissen wie sich anhand des Momentums die Kurve entwicklen könnte und vielleicht noch andere Darstellungsformen zu entwickeln. Vielleicht wären hier Mathematiker ganz gut. Ich wäre als Informatiker jedenfalls dabei! | ||
Formulierung Herausforderung | Formulierung Herausforderung | ||
Wir können einfach darstellen ob die getroffenen Maßnahmen Wirkung zeigen. | Wir können einfach darstellen ob die getroffenen Maßnahmen Wirkung zeigen. | ||
== Ziele == | == Ziele == | ||
* | * saubere und strukturierte Daten | ||
* Datengrundlage in Deutschland | |||
* Zeitreihen-Analyse | |||
* Zusammenhang zwischen Eindämmungsmassnahmen und Zeitreihen-Daten | |||
* Verzögerung durch Inkubationszeit berücksichtigen | |||
* Vergleich mit Ländern in denen die Wirkung schon eingetreten ist: China, Korea, Taiwan, ... | |||
* Mapping Region Bevölkerungszahl siehe https://github.com/paul-em/covid-19-curves/blob/master/assets/populations.js | |||
* Anwendern die Angst und Ungewissheit über die zukünftige Entwicklung nehmen. Exponentiell hört sich für die einen schrecklich an, die anderen nehmen es nicht ernst. Ein Satz wie "Im April brauchen wir 500.000 Krankenhausbetten" hilft es besser einzuordnen. | |||
* Anwendern die Notwendigkeit und Effizienz von Maßnahmen der Regierung aufzuzeigen. Eine Ausgangssperre ist hart, aber wenn man zeigt, dass wir dann im April doch nur 100.000 Krankenhausbetten brauchen, wird es vielleicht akzeptiert. Fakt ist: Bisherige Tools sind unzureichend, was die Prognose für die Zukunft anbelangt. "Flattening the curve" ist für den Mathematiker cool, für viele andere Menschen unverständlich. | |||
== Vorgehen == | == Vorgehen == | ||
=== Teambildung === | |||
* Modellierung | |||
** Netzwerke | |||
** SIR Modelle | |||
** Statistische Modelle | |||
* Datawarehousing | |||
* Visualization | |||
=== Kommunikation === | |||
* Strukturierte Dokumentation hier | |||
* Metadokument/Organisation: https://docs.google.com/document/d/1DMAisYOtO1RZU7OVzppxrlRGVhjzJNq3eRiKbNHKC-g/edit# | |||
* Slack-Channel für Architektur: https://wirvsvirus.slack.com/archives/C010G6FAL00 | |||
** Architektur-Entwurf: https://docs.google.com/document/d/1K1_plqtRlrpn2tjNohiEXPTrNDtBRq2F13HqvTA1-Lo/edit# | |||
==== Idee ==== | |||
* Backendleute vieleicht um DB und REST-API kümmern, Mathematiker um modelle und Frontendleute um die darstellung und dann noch datenquellen gesammeltwerden. | |||
* 21:25 Uhr kleine Gruppe 3 Leute: probabilistische Modellieren mit Unsicherheiten | |||
* 21:38 Uhr Ich würde gerne ein Team für das data warehousing mit ein paar leuten machen. | |||
* 21:37 Uhr Datenrecherche | |||
* 21:45 Uhr Visualisierung - Gruppe um 22:02 Uhr erstellt | |||
* 21:48 Uhr statistische Modelle | |||
=== Ideen === | === Ideen === | ||
* Aufbauend auf diesem Open-Source Projekt könnte weitergearbeitet werden: https://paul-em.github.io/covid-19-curves/Andere Ansätze gibts es bereits einige. | * Aufbauend auf diesem Open-Source Projekt könnte weitergearbeitet werden: https://paul-em.github.io/covid-19-curves/Andere Ansätze gibts es bereits einige. | ||
| Line 26: | Line 82: | ||
* quasi md simulationen mit ansteckung bei interaktionen | * quasi md simulationen mit ansteckung bei interaktionen | ||
* ein dashboard bauen was als frontend dienen könnte | * ein dashboard bauen was als frontend dienen könnte | ||
* Mit http://www.bitplan.com/index.php/SimpleGraph könnte aus den CSV eine Graph-Datenbank gemacht und anschliessend mit Geo-Daten usw. verknüpft werden, damit wir Datenformate bekommen, die wir besser nutzen können. | |||
* Json und CSV wäre sinnvoll | |||
* Prognosen bieten sich generell verschiedene Ansätze an: 1. Fit der Daten an epidemiologische Modelle 2. Vergleich der Daten mit anderen Ländern (Italien, Südkorea, China) 3. Abschätzung durch Veränderungen im aktuellen Datensatz | |||
* Susceptible Pool wichtig, also die Bevölkerungszahl %of pop infected e.g. Diamond P=23.58% 0.02 % China, 0.12% Norway | |||
* Gesamtarchitektur/Schnittstellen-Festlegung zwischen Daten, Modellierung und Visualisierung? | |||
==== Vorgehensvorschlag ==== | |||
* Daten und Events (Maßnahmen) sammeln | |||
* Modellierung, die daraus die Zukunft vorhersagen kann | |||
* Visualisierung der Zukunft (ähnlich Wettervorhersage) | |||
* Interaktive Visualisierung bei der sich einzelen Events abschalten lassen und die Folgen sichtbar sind (aus den Modellen abgeleitet) | |||
== Wie geht's weiter == | |||
* https://docs.google.com/document/d/1NZq-Z20SNLKVOdQ41oOLgRZMFpXAW-7sRi1U4-kD9_0/edit?usp=sharing | |||
= Links = | = Links = | ||
| Line 35: | Line 104: | ||
* https://github.com/CSSEGISandData/COVID-19 | * https://github.com/CSSEGISandData/COVID-19 | ||
* https://www.ecdc.europa.eu/en/geographical-distribution-2019-ncov-cases | * https://www.ecdc.europa.eu/en/geographical-distribution-2019-ncov-cases | ||
* http://gabgoh.github.io/COVID/index.html | * Epidemic Calculator: http://gabgoh.github.io/COVID/index.html | ||
* https://npgeo-corona-npgeo-de.hub.arcgis.com/datasets/917fc37a709542548cc3be077a786c17_0/data | |||
* https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Fallzahlen.html | |||
* https://de.wikipedia.org/wiki/COVID-19-Pandemie_in_Deutschland | |||
* https://de.wikipedia.org/wiki/SIR-Modell | |||
* https://www.dgepi.de/assets/Stellungnahmen/Stellungnahme2020Corona_DGEpi-20200319.pdf | |||
* https://www.sueddeutsche.de/politik/coronavirus-niederlande-herdenimmunitaet-1.4850134 | |||
= Germany = | = Germany = | ||
| Line 41: | Line 116: | ||
* https://www.tagesschau.de/inland/coronavirus-karte-deutschland-101.html | * https://www.tagesschau.de/inland/coronavirus-karte-deutschland-101.html | ||
[[Category:WirVsVirus]] | [[Category:WirVsVirus]] | ||
= Copy of google Doc = | |||
see https://docs.google.com/document/d/1DMAisYOtO1RZU7OVzppxrlRGVhjzJNq3eRiKbNHKC-g/edit# | |||
== Challenge #1757 == | |||
=== Titel Predict the Curve Flattening === | |||
=== Challenge ID 1757 Predict the Curve Flattening === | |||
=== Join DevPost === | |||
* https://devpost.com/software/1757_flattenthecurve_predictivemodeling-tyeo67/joins/fbU5llTy-nL2uIv5vcC8kQ | |||
=== Kategorie Kommunikation & Informationsvermittlung an Bürger*innen === | |||
=== Daten: Wie können wir Daten besser aufbereiten und nutzen? === | |||
== Task == | |||
Jeder redet von #flattenthecurve aber wie sieht die Kurve eigentlich aus und wie entwickelt sie sich? Ich habe in den letzten Tagen bereits eine Open-Source Visualisierung mit Daten der John Hopkins University gemacht: https://paul-em.github.io/covid-19-curves/ Spannend wäre allerdings zu wissen wie sich anhand des Momentums die Kurve entwickeln könnte und vielleicht noch andere Darstellungsformen zu entwickeln. Vielleicht wären hier Mathematiker ganz gut. Ich wäre als Informatiker jedenfalls dabei! Formulierung Herausforderung Wir können einfach darstellen ob die getroffenen Maßnahmen Wirkung zeigen. | |||
== Getting started == | |||
Du bist später dazu gekommen und magst helfen? | |||
Wir sind in subgruppen organisiert. Suche dir eine subgruppe aus und trete dieser auf Slack bei. Solltest du die Gruppe nicht auf Slack finden, dann haben sind die Leute immer noch nicht in eine öffentliche Gruppe umgezogen [ :( ]. Schreibe dann am besten die verantwortlichen Person und lass dich hinzufügen. Das weitere Vorgehen ist in den Subgruppen beschrieben | |||
== Ziele == | |||
* saubere und strukturierte Daten | |||
* Datengrundlage in Deutschland | |||
* Zeitreihen-Analyse | |||
* Zusammenhang zwischen Eindämmungsmassnahmen und Zeitreihen-Daten | |||
* Verzögerung durch Inkubationszeit berücksichtigen | |||
* Vergleich mit Ländern in denen die Wirkung schon eingetreten ist: China, Korea, Taiwan, ... | |||
* Mapping Region Bevölkerungszahl siehe https://github.com/paul-em/covid-19-curves/blob/master/assets/populations.js | |||
* Anwendern die Angst und Ungewissheit über die zukünftige Entwicklung nehmen. Exponentiell hört sich für die einen schrecklich an, die anderen nehmen es nicht ernst. * Ein Satz wie "Im April brauchen wir 500.000 Krankenhausbetten" hilft es besser einzuordnen. | |||
* Anwendern die Notwendigkeit und Effizienz von Maßnahmen der Regierung aufzuzeigen. Eine Ausgangssperre ist hart, aber wenn man zeigt, dass wir dann im April doch nur 100.000 Krankenhausbetten brauchen, wird es vielleicht akzeptiert. Fakt ist: Bisherige Tools sind unzureichend, was die Prognose für die Zukunft anbelangt. "Flattening the curve" ist für den Mathematiker cool, für viele andere Menschen unverständlich. | |||
* Berücksichtigung verfügbarer Krankenhauskapazitäten e.g. https://link.springer.com/article/10.1007/s00134-012-2627-8 | |||
* Datenaktualität für die Zukunft sicherstellen | |||
== Vorgehen == | |||
Devpost Projekt anlegen ähnlich https://devpost.com/software/lake-covid | |||
== Kommunikation == | |||
Zoom: https://stanford.zoom.us/j/3845589503 | |||
Gruppen-Channels: siehe unten | |||
== Ideen == | |||
*Aufbauend auf diesem Open-Source Projekt könnte weitergearbeitet werden: https://paul-em.github.io/covid-19-curves/ Andere Ansätze gibts es bereits einige. | |||
*Wäre es nicht sinnvoll ein datenbank cluster aufzusetzen um die Daten zentral zu sammeln. Dann könne wir die verschiedenen Tools gegen dieselbe Datenbasis laufen lassen und testen welche Algorithmen die besten sind und die Daten zusammenführen | |||
*Epidemic Calculator | |||
* predictions mit lstm, dense oder whatever nn ihr mögt | |||
*disease equations fitten | |||
*quasi md simulationen mit ansteckung bei interaktionen | |||
*ein dashboard bauen was als frontend dienen könnte | |||
*Mit http://www.bitplan.com/index.php/SimpleGraph könnte aus den CSV eine Graph-Datenbank gemacht und anschließend mit Geo-Daten usw. verknüpft werden, damit wir *Datenformate bekommen, die wir besser nutzen können. | |||
Json und CSV wäre sinnvoll | |||
* Prognosen bieten sich generell verschiedene Ansätze an: 1. Fit der Daten an epidemiologische Modelle 2. Vergleich der Daten mit anderen Ländern (Italien, Südkorea, China) 3. Abschätzung durch Veränderungen im aktuellen Datensatz | |||
* Susceptible Pool wichtig, also die Bevölkerungszahl %of pop infected e.g. Diamond P=23.58% 0.02 % China, 0.12% Norway | |||
* Gesamtarchitektur/Schnittstellen-Festlegung zwischen Daten, Modellierung und Visualisierung? | |||
* In every group one member should be in charge of communicating with the other sub-groups, to ensure good communication between all groups. | |||
Vorgehensvorschlag | |||
* Daten und Events (Maßnahmen) sammeln | |||
* Modellierung, die daraus die Zukunft vorhersagen kann | |||
* Visualisierung der Zukunft (ähnlich Wettervorhersage) | |||
* Interaktive Visualisierung bei der sich einzelne Events abschalten lassen und die Folgen sichtbar sind (aus den Modellen abgeleitet) | |||
== Workspaces == | |||
* Devpost https://devpost.com/software/1_038_a_daten_datawarehousing | |||
* [[Predict the Curve Flattening|Wiki]] | |||
* [https://drive.google.com/drive/folders/1ugrnhXxMN_4SK6hFWnm6bABHlDXa5mMr Google Drive] | |||
== Organisation == | |||
Organisationsstruktur und Data Flow | |||
Data Collection -> | |||
Data API -> | |||
Modeling | |||
<- Visualization | |||
Architecture | |||
Overview of Subgroups | |||
Responsible | |||
Sub-Group | |||
Slack Chat Name | |||
Paul Em | |||
Visualisierung | |||
#challenge 1757 visualisierung | |||
Tobias Hölzer | |||
Data API | |||
#1757_datensammlung | |||
Elias Küpper <3 | |||
Architektur | |||
#1757_architektur | |||
Tobias Hofmann | |||
Data Collection | |||
#1757_datensammlung | |||
Vroni Bierbaum | |||
Modellierung | |||
#1757_modellierung | |||
Architektur (DE) | |||
#1757_architektur | |||
This group tries to create a common solution out of the parts developed by the other working groups: | |||
https://docs.google.com/document/d/1K1_plqtRlrpn2tjNohiEXPTrNDtBRq2F13HqvTA1-Lo/edit# | |||
Communication Channel: #1757_architektur | |||
Contact for Channel: Elias Küpper | |||
Data Collection (DE) | |||
The data collection group is collecting data on measures ordered by local or federal governments here: | |||
https://docs.google.com/spreadsheets/d/1CW99DTTWFO5T3oiERzRaHGqpAQ_J-3PfwaMibUgJp4Y/edit#gid=262317549 | |||
An overview of available Data: | |||
https://docs.google.com/spreadsheets/d/13la9BFcPUeZKnx6amfwogzmhcNxtF_ouBiV6aOpDHFM/edit#gid=0 | |||
Communication Channel: # 1757_datensammlung | |||
Contact for Channel: Tobias Hofmann, Berit Zeller-Plumhoff | |||
Data Warehouse (DE) | |||
Problemstellung: Gesammelte Roh-Daten zu strukturieren und in einer NoSQL Datenbank (MongoDB) um diese strukturierten Daten nun mittels einer REST API zur Verfügung zu stellen. | |||
Communication Channel: #challenge-1757-datawarehouse | |||
Contact for Channel: Tobias Hölzer | |||
== Data Collection == | |||
* https://bene.gridpiloten.de:4712/api/ui | |||
<uml> | |||
hide circle | |||
class Cases { | |||
_id | |||
date | |||
adm | |||
ageRange | |||
sex | |||
infected | |||
dead | |||
recovered | |||
tested | |||
Source | |||
} | |||
class Measures { | |||
_id | |||
date | |||
adm | |||
border_control | |||
home_office | |||
closure_leisureandbars | |||
lockdown | |||
schools_closed | |||
traveller_quarantine | |||
primary_residence | |||
test_limitations | |||
misc | |||
source | |||
compliance_estimate | |||
compliance_source | |||
} | |||
</uml> | |||
== Visualization (DE + EN) == | |||
Wir, im Team Visualisierung, versuchen jetzt mal mit den bestehenden Daten einfach noch mehr insights zu den Kurvenverläufen zu generieren ohne aufwändige Berechnungen, gerne können wir hier auch Designer aufnehmen. Ich denke es macht sehr viel Sinn wenn es ein Team gibt, das sich spezialisiert darauf mit welchen Statistischen Berechnungen man hier noch den weiteren Verlauf berechnen kann und welche Daten dafür noch notwendig sind. Darauf aufbauend könnten wir dann im Team Datamodelling versuchen diese Daten zu bekommen, aggregieren und bereitzustellen | |||
We are currently working on implementing first simple tools into the pre-existing visualization on https://paul-em.github.io/covid-19-curves/ to display and predict the total number of confirmed cases (currently only using oversimplified models :). | |||
Use confirmed published data of “early” countries (China, South Korea, Italy) as a tool to compare confirmed cases with confirmed cases of “late” countries | |||
The infections started in some countries earlier than in others. The goal of this subproject is to take advantage of the published daily official data (confirmed cases, confirmed deaths, confirmed recoveries available in open databases such as JHU CSSE https://github.com/CSSEGISandData/COVID-19) to predict the development in countries with delayed outbreaks. | |||
We define the start of the outbreak as the first day, where the total number of confirmed cases exceeded a chosen threshold value (e.g. 200 confirmed cases). Countries with cases below this this threshold value are often capable of confining the outbreak. However, as soon as this threshold is reached, infections can often no longer be contained and the number of total cases increases exponentially (logistical growth). By comparing the data with “early” countries, the number of confirmed cases can be estimated for “late” countries. | |||
=== How === | |||
==== Open questions & tasks: ==== | |||
Question: How to account for differences between countries? (population size, Case definitions, testing capabilities, community spread, number of infected clusters, … ) | |||
* How can we adjust the data/display the data in a useful manner to account for these differences? | |||
* Maybe change subgroup name to “Predictive Data Visualization/Comparison/Forecast” or similar? | |||
* Task: Create database containing country differences (ideally in csv format see JHU CSSE). Team database? | |||
* Task: Display actions taken by each country, link to each data point in plot/display in plots? (e.g.: *country*, *date*, *action*; “Germany, 14/03/2020, Closing Schools”) Team database? | |||
* Task Disclaimer: How does test capacity and case definition affect the graphs? | |||
Status: First implementation of timeshifted plots completed, currently two team members | |||
*Which features in the final product/prototype? | |||
Disclaimer: What can be inferred from the displayed information? What can NOT be inferred? How can we communicate this uncertainty clearly? | |||
Sharing Views? | |||
Display the effect of taken actions (isolation, social distancing) | |||
Tool to fit simple models (e.g. logistic growth) to the available published data without making any additional assumptions or simulations | |||
E.g. Inflection point analysis tool, logistic curve tool | |||
Goal: Roughly predict the curve flattening by fit to logistic function (when the growth of total number of confirmed cases is expected to slow down; see time series of total confirmed cases China, South Korea slowing down at around 80000, 8000 cases). | |||
Status: Nobody actively working on this yet | |||
Implementation of advanced models (data from modeling group) | |||
Status: Nobody actively working on this yet. Waiting for data from modeling group. | |||
Communication Channel: #challenge_1757_visualisierung | |||
Contact for Channel: Paul Em (/ Paul Frml) | |||
=== Modeling (DE) === | |||
General Communication Channel within modeling : #1757_modellierung | |||
The Modeling group has organised themselves in further subgroups. The subgroups will use different methods to implement the models. | |||
The methods and subgroups are: | |||
Ordinary differential equations: https://wirvsvirus.slack.com/archives/C0103T4RPR8 | |||
Stochastic simulation: https://wirvsvirus.slack.com/archives/C0106K0PCM7 | |||
Machine Learning #1757_modellierung_ml | |||
Please join the slack channels, if you want to work in the group. | |||
Github: (public) https://github.com/joshuakuepper/Challenge-1757 | |||
Subgruppe ODE: | |||
Zoom-Meeting: | |||
Wir haben uns dazu entschieden das SEIR Modell in Python zu implementieren. Dafür wird der Code auf Github geteilt: https://github.com/joshuakuepper/Challenge-1757/tree/master/deterministic_models | |||
Die Parameter werden aus Veröffentlichungen von Instituten entnommen. | |||
Veröffentlichung des RKI zur Entnahme von Parametern: https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Modellierung_Deutschland.pdf?__blob=publicationFile | |||
Stellungnahme der Deutschen Gesellschaft für Epidemiologie zur Entnahme von Parametern: | |||
https://www.dgepi.de/assets/Stellungnahmen/Stellungnahme2020Corona_DGEpi-20200319.pdf | |||
R0 könnte von der ML Gruppe als Zeitreihe je nach erforderlicher Maßnahme gegeben werden. Die anderen Parameter kommen aus den og Publikationen. Das Modell wurde etwas erweitert, die Modellparameter müssen aber irgendwoher kommen (ML Gruppe? Publikationen?) | |||
Weitere relevante Links: | |||
Simulating COVID-19 interventions with R | |||
Pandemic Preparedness Planning for COVID-19: http://covidsim.eu/ | |||
Paper zum Modellierung: https://arxiv.org/pdf/2003.06031v1.pdf | |||
SEIR model + dashboard: https://neherlab.org/covid19/ | |||
SEIR model visualisierung:https://gabgoh.github.io/COVID/index.html | |||
Estimating actual COVID 19 cases (novel corona virus infections) in an area based on deaths: | |||
<youtube>mCa0JXEwDEk</youtube> | |||
https://www.youtube.com/watch?v=mCa0JXEwDEk | |||
=== Sub-gruppe Stochastic Model: === | |||
Zoom-Meeting: https://ethz.zoom.us/j/666255196 | |||
Start with basic stochastic SIR model: | |||
S + I -> 2*I with probability 0.025 | |||
I -> R | |||
Df | |||
N particles, each has a label (S/I/R) | |||
Each day, each particle chooses m (13.3?) other particles uniformly at random | |||
When a S and a I particle meet, w.p. p(=0.025?), the S particle becomes I | |||
Each particle has a exponential recovery distribution (median 5), when that time is up they become R | |||
Let S, I, R denote the number of each particles (so that N=S+I+R). | |||
We are only interested in contacts where one of the two particles is of type I and the other is S. | |||
In total, we have Nm collisions and the probability of one of them being S and the other I is SI/N^2. Further, for every contact, with probability p we have transmission. Therefore, the number of new infections (S->I) is distributed according to a Bin(Nm, S*I*p/N^2). | |||
Moreover, if we assume that the recovery time follows an exponential distribution, the probability of a patient having had the disease for k days recovering today is 1-e^(-L) where L is the parameter of the exponential distribution. (Gets more complicated for double exponential: will depend on k.) Thus, the number of recoveries (I->R) is Bin(I,1-e^(-L)). | |||
In summary: the numbers S, I, R follow a simple progression: each day | |||
S->S - A | |||
I-> I + A-B | |||
R-> R+B | |||
Where A, B are independent, A~Bin(Nm, S*I*p/N^2) and B~Bin(I,1-e^(-L)). | |||
Extensions: | |||
Do this for several communities, add interaction term between each community | |||
Add an “exposed” group, assuming that once individuals show symptoms (i.e. they know they are I), they will seek fewer contacts | |||
Model different government intervention as reducing the average number of contacts m | |||
Parameter fitting? | |||
Relation to visualisation | |||
Quantitative forecasts: | |||
jangevaare/Pathogen.jl: Simulation, visualization, and inference tools for modelling the spread of infectious diseases with Julia | |||
Modeling COVID-19 Spread vs Healthcare Capacity | |||
coronafighter/coronaSEIR: Simple SEIR model Python script for the COVID-19 pandemic with real world data comparison. | |||
Impact of non-pharmaceutical interventions (NPIs) to reduce COVID- 19 mortality and healthcare demand | |||
http://gabgoh.github.io/COVID/index.html | |||
Develop models for practical forecasts of cases of infections, ICU cases and deaths. Many possible approaches: | |||
Model des | |||
Statistical models | |||
Timeseries | |||
Arima - Schwer Anzuwenden | |||
Regression | |||
Death yes/no - logistische Regression (Logit-Modell) | |||
Bestimmte Anzahl an Erkrankten prognostizieren - “klassische” Regression | |||
parametric timing distributions (Poisson/Weibull) for infection: | |||
https://arxiv.org/pdf/1009.4362.pdf | |||
https://www.wiwi.uni-muenster.de/fbach/ | |||
==== Examples ==== | |||
* http://www.scholarpedia.org/article/State_space_model | |||
* https://en.wikipedia.org/wiki/Error_correction_model | |||
* https://github.com/sarahhbellum/NobBS | |||
* https://towardsdatascience.com/modeling-exponential-growth-49a2b6f22e1f | |||
==== SEIR ==== | |||
Groups: Susceptible, Infected, Exposed (affected, not spreading), Recovered… | |||
Deterministisch (DGLs) oder stochastisch | |||
https://gabgoh.github.io/COVID/index.html | |||
https://rviews.rstudio.com/2020/03/19/simulating-covid-19-interventions-with-r/ (EpiModel) | |||
Idea: Include detected and dead (reliable data available!), fit model parameters to known data, estimate real number of exposed | |||
We need to separate two subgroups: 1) parameter fitting and 2) simulation given a set of parameters | |||
Combination of network models and contagion models: https://arxiv.org/abs/1408.2701 | |||
Epidemiological models (calibrated). | |||
Interlinked Systems of SIR/SIS models (to add a spatial component for cities, counties etc.) | |||
https://arxiv.org/pdf/1701.03137.pdf | |||
Stochastic SIR/SIS models | |||
https://staff.math.su.se/hoehle/blog/2020/03/16/flatteningthecurve.html | |||
(https://rviews.rstudio.com/2020/03/19/simulating-covid-19-interventions-with-r/) | |||
(https://wirvsvirus.slack.com/files/U01049R3EUB/F0105VC5657/pan2014.pdf) / https://link.springer.com/article/10.1007/s11203-014-9091-8 | |||
https://github.com/CEIDatUGA/ncov-wuhan-stochastic-model | |||
More general Markov chain models on graphs to model more hypotheses (quarantines, border closures, social distancing…) | |||
The Imperial College model focus is on NPI, or predicting the virus spread as a function of different strategies, such as suppression of social contacts, or mitigation alone. The impact of the latter is a dramatic number of deaths, and some optimum strategies are developed that aggregate different containment measures in time. | |||
https://www.kaggle.com/c/covid19-global-forecasting-week-1/notebooks | |||
Machine Learning Methods | |||
NN / Gradient Boosting / Random Forest; also connectable with network model | |||
Zeitreihen per LSTM etc. | |||
https://www.wsj.com/articles/scientists-crunch-data-to-predict-how-many-people-will-get-coronavirus-11584479851 | |||
CBCV model: https://www.wiwi.uni-muenster.de/fbach/ | |||
Tools (dedicated statistical software packages): (add short descriptions?) | |||
Package 'bsts' | |||
*https://cran.r-project.org/web/packages/dlm/dlm.pdf | |||
*https://www.statsmodels.org/stable/index.html | |||
*https://www.gnu.org/software/octave/ | |||
R0 package (estimation of basic reproduction rate), article: https://www.ncbi.nlm.nih.gov/pubmed/23249562 | |||
Illustrative / qualitative models: | |||
Network models (e.g. SIR on graph) | |||
Qualitative epidemiological models | |||
Graph theory : firefighters | |||
Tools (dedicated illustrative models): | |||
Network models: | |||
More info: https://github.com/patrickfrank1/covid-19-project164 | |||
Communication Channel: #1757_modellierung | |||
Contact for Channel: Vroni Bierbaum | |||
=== Simulationen === | |||
* http://covidsim.eu/ | |||
* Epidemic Calculator: http://gabgoh.github.io/COVID/index.html | |||
**Source code: https://github.com/gabgoh/epcalc | |||
* https://web.br.de/interaktiv/corona-simulation/ | |||
* https://covid19visualiser.com/ | |||
** Source code: https://github.com/patricknasralla/covid19_3D_visualisation | |||
=== Datensätze / Links === | |||
* [https://www.europeandataportal.eu/data/datasets/covid-19-coronavirus-data?locale=en EuropeanDataPortal Datensätze zur Weltweiten Corona-Ausbreitung] | |||
* [https://www.govdata.de/web/guest/suchen/-/details/personal-in-krankenhausern-deutschland-stichtag Personal in Krankenhäusern in Deutschland (1991-2017)] | |||
* [https://www.govdata.de/web/guest/suchen/-/details/mautdaten-bund Mautdaten Bund - Indikator für kurzfristige Entwicklungen der wirtschaftlichen Situation] | |||
* [https://npgeo-corona-npgeo-de.hub.arcgis.com/search?groupIds=b28109b18022405bb965c602b13e1bbc RKI Daten Bundesländer] | |||
* [https://npgeo-corona-npgeo-de.hub.arcgis.com/datasets/dd4580c810204019a7b8eb3e0b329dd6_0/geoservice?orderBy=AnzahlFall&orderByAsc=false RKI Daten Landkreise] | |||
* [https://github.com/CSSEGISandData/COVID-19 Johns Hopkins CSSE (.csv)] | |||
* [https://github.com/ExpDev07/coronavirus-tracker-api Johns Hopkins CSSE Daten (REST-API)] | |||
* [https://data.europa.eu/euodp/en/data/dataset/covid-19-coronavirus-data/resource/55e8f966-d5c8-438e-85bc-c7a5a26f4863 EU-Open Data-Portal (.csv)] | |||
* [https://www.euromomo.eu/ Euromomo - Mortality Monitoring EU] | |||
Feed of hostnames found in certificate transparency logs that are related to the COVID-19 pandemic (.csv): | |||
https://1984.sh/covid19-domains-feed.txt | |||
Kaggle: Daily Cases of Corona (.csv) | |||
https://www.kaggle.com/sudalairajkumar/novel-corona-virus-2019-dataset | |||
Corona Cases Schweiz (.csv) | |||
https://github.com/daenuprobst/covid19-cases-switzerland | |||
GovData | |||
https://www.govdata.de/ | |||
COVID-19 / SARS-CoV-2 resources | |||
https://gehrcke.de/2020/03/covid-19-sars-cov-2-resources/ | |||
Point of Interest Daten | |||
www.algoly.com | |||
Alle POI-Daten verfügbar mittels einfacher API oder self publishing in Excel. Abrufbar auf Adresse genau oder großem Radius. Algoly übernimmt bei #WirvsVirus Projekten die Serverkosten und können viele Daten kostenfrei oder zum EK-Preis zur Verfügung stellen. Schicke einfach dirk@algoly.com eine mail | |||
Demografische & Soziografische Daten | |||
www.algoly.com | |||
Demografische und Soziografische-Daten (Einkommensstruktur, Alter, Bildung, etc.) verfügbar mittels einfacher API oder self publishing ins | |||
Excel. Abrufbar auf Adresse genau oder großem Radius. Algoly übernimmt bei #WirvsVirus Projekten die Serverkosten und können viele Daten | |||
kostenfrei oder zum EK-Preis zur Verfügung stellen. Schicke einfach dirk@algoly.com eine mail | |||
COVID-19 image data collection | |||
https://github.com/ieee8023/covid-chestxray-dataset | |||
JSON mit gemeldeten CORONA Fällen auf Landkreis | |||
https://services7.arcgis.com/mOBPykOjAyBO2ZKk/arcgis/rest/services/RKI_COVID19/FeatureServer/0/query?where=1%3D1&outFields=*&outSR=4326&f=json | |||
Achtung! Nur die ersten 2000 Datensätze. Für mehr muss paging verwendet werden! | |||
Coronavirus Disease (COVID-19) – Statistics and Research | |||
https://ourworldindata.org/coronavirus | |||
XAPIX Service Endpoints für verschiedene COVID-19 Daten | |||
https://www.xapix.io/covid-19-initiative | |||
Covid19API (stabile API mit versch Endpunkten basierend auf John Hopkins Daten), Krankenhausbetten (leider nur Californien), point of interest Daten | |||
Übersicht in Deutschland | |||
https://www.citypopulation.de/de/germany/covid/ | |||
Aufteilung nach Bundeländern | |||
Mobilitätsdaten Portale | |||
https://gobeta.de/projekte/dataportale/ | |||
Manuelle Liste DE nach Landkreisen | |||
https://docs.google.com/spreadsheets/d/1wg-s4_Lz2Stil6spQEYFdZaBEp8nWW26gVyfHqvcl8s/htmlview# | |||
Kaggle Forecast Dataset Sharing | |||
https://www.kaggle.com/c/covid19-global-forecasting-week-1/discussion/137078 | |||
*https://paul-em.github.io/covid-19-curves/ | |||
*https://github.com/paul-em/covid-19-curves | |||
*http://www.wiwi.uni-muenster.de/fbach/ | |||
*https://de.wikipedia.org/wiki/Coronavirus-Epidemie_2019/2020 | |||
*https://www.thelancet.com/journals/laninf/article/PIIS1473-3099(20)30120-1/fulltext | |||
*https://github.com/CSSEGISandData/COVID-19 | |||
*https://www.ecdc.europa.eu/en/geographical-distribution-2019-ncov-cases | |||
*https://npgeo-corona-npgeo-de.hub.arcgis.com/datasets/917fc37a709542548cc3be077a786c17_0/data | |||
*https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Fallzahlen.html | |||
*https://de.wikipedia.org/wiki/COVID-19-Pandemie_in_Deutschland | |||
*https://de.wikipedia.org/wiki/SIR-Modell | |||
*https://www.dgepi.de/assets/Stellungnahmen/Stellungnahme2020Corona_DGEpi-20200319.pdf | |||
*https://www.sueddeutsche.de/politik/coronavirus-niederlande-herdenimmunitaet-1.4850134 | |||
*https://interaktiv.tagesspiegel.de/lab/karte-sars-cov-2-in-deutschland-landkreise/ | |||
*https://www.tagesschau.de/inland/coronavirus-karte-deutschland-101.html | |||
*https://www.washingtonpost.com/graphics/2020/world/corona-simulator/ | |||
*https://www.spiegel.de/wissenschaft/medizin/corona-krise-lockdown-koennte-bis-ins-naechste-jahr-dauern-a-ea2e318b-b388-4ccc-8493-318f892381b8 | |||
*https://blog.datawrapper.de/coronaviruscharts/ | |||
*https://ourworldindata.org/coronavirus#growth-country-by-country-view | |||
*https://neherlab.org/covid19/ | |||
*https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Modellierung_Deutschland.pdf | |||
*http://shinyapps.org/apps/corona/ | |||
*https://chschoenenberger.shinyapps.io/covid19_dashboard/ | |||
=== Other challenges which might be helpful === | |||
0284 (Dunkelziffer schätzen) | |||
0982 (Dunkelziffer radar) | |||
0361 (Wie schaffen wir es eine realistische Schätzung von Zahlen für Infizierte zu bekommen und wie schaffen wir es neue Infektionsherde zu finden?) | |||
#herausforderung 0999 (Übersicht über Zahlen und Kurven der aktuellen weltweiten Situation mit Extrapolation in die Zukunft) | |||
#https://devpost.com/software/lake-covid | |||
## https://github.com/WirVSVirus-Data-Collection | |||
#https://devpost.com/software/038_daten_infektionszahlenschatzen | |||
<youtube>ug6u5wXXD4M</youtube> | |||
==== 044 Flattenthecurve Optimize the curve ==== | |||
* https://devpost.com/software/1_044_b_flatten-the-curve_optimize-the-curve | |||
<youtube>N3yKUk_tfBY</youtube> | |||
* http://covidsim.eu/ | |||
Latest revision as of 13:53, 3 April 2020

Result
- https://youtu.be/bhWTAO7oQuo
- https://paul-em.github.io/wir-vs-virus/
- https://devpost.com/software/1757_flattenthecurve_predictivemodeling-tyeo67
Comparable Results
- https://devpost.com/software/what-can-i-do-changing-my-behavior-changes-the-curve
- https://devpost.com/software/01_008_corona_tracking_predictive_risk_area_modeling
- https://devpost.com/software/038_daten_flatcurver
- https://devpost.com/software/1_044_b_flatten-the-curve_optimize-the-curve
COVID-19 Simulation
Johns Hopkins University Data
Slack
herausforderung_164 is the channel you can ask for an invitation on slack channel 1_038_a_daten
Active structured documentation is now at https://docs.google.com/document/d/1DMAisYOtO1RZU7OVzppxrlRGVhjzJNq3eRiKbNHKC-g/edit#
Organisation
Aufgabe
Titel Predict the Curve Flattening
Kategorie Kommunikation & Informationsvermittlung an Bürger*innen
Daten: Wie können wir Daten besser aufbereiten und nutzen?
Probleme
Jeder redet von #flattenthecurve aber wie sieht die Kurve eigentlich aus und wie entwickelt sie sich? Ich habe in den letzten Tagen bereits eine Open-Source Visualisierung mit Daten der John Hopkins University gemacht: https://paul-em.github.io/covid-19-curves/Spannend wäre allerdings zu wissen wie sich anhand des Momentums die Kurve entwicklen könnte und vielleicht noch andere Darstellungsformen zu entwickeln. Vielleicht wären hier Mathematiker ganz gut. Ich wäre als Informatiker jedenfalls dabei! Formulierung Herausforderung Wir können einfach darstellen ob die getroffenen Maßnahmen Wirkung zeigen.
Ziele
- saubere und strukturierte Daten
- Datengrundlage in Deutschland
- Zeitreihen-Analyse
- Zusammenhang zwischen Eindämmungsmassnahmen und Zeitreihen-Daten
- Verzögerung durch Inkubationszeit berücksichtigen
- Vergleich mit Ländern in denen die Wirkung schon eingetreten ist: China, Korea, Taiwan, ...
- Mapping Region Bevölkerungszahl siehe https://github.com/paul-em/covid-19-curves/blob/master/assets/populations.js
- Anwendern die Angst und Ungewissheit über die zukünftige Entwicklung nehmen. Exponentiell hört sich für die einen schrecklich an, die anderen nehmen es nicht ernst. Ein Satz wie "Im April brauchen wir 500.000 Krankenhausbetten" hilft es besser einzuordnen.
- Anwendern die Notwendigkeit und Effizienz von Maßnahmen der Regierung aufzuzeigen. Eine Ausgangssperre ist hart, aber wenn man zeigt, dass wir dann im April doch nur 100.000 Krankenhausbetten brauchen, wird es vielleicht akzeptiert. Fakt ist: Bisherige Tools sind unzureichend, was die Prognose für die Zukunft anbelangt. "Flattening the curve" ist für den Mathematiker cool, für viele andere Menschen unverständlich.
Vorgehen
Teambildung
- Modellierung
- Netzwerke
- SIR Modelle
- Statistische Modelle
- Datawarehousing
- Visualization
Kommunikation
- Strukturierte Dokumentation hier
- Metadokument/Organisation: https://docs.google.com/document/d/1DMAisYOtO1RZU7OVzppxrlRGVhjzJNq3eRiKbNHKC-g/edit#
- Slack-Channel für Architektur: https://wirvsvirus.slack.com/archives/C010G6FAL00
Idee
- Backendleute vieleicht um DB und REST-API kümmern, Mathematiker um modelle und Frontendleute um die darstellung und dann noch datenquellen gesammeltwerden.
- 21:25 Uhr kleine Gruppe 3 Leute: probabilistische Modellieren mit Unsicherheiten
- 21:38 Uhr Ich würde gerne ein Team für das data warehousing mit ein paar leuten machen.
- 21:37 Uhr Datenrecherche
- 21:45 Uhr Visualisierung - Gruppe um 22:02 Uhr erstellt
- 21:48 Uhr statistische Modelle
Ideen
- Aufbauend auf diesem Open-Source Projekt könnte weitergearbeitet werden: https://paul-em.github.io/covid-19-curves/Andere Ansätze gibts es bereits einige.
- Wäre es nicht sinnvoll ein datenbank cluster aufzusetzen um die Daten zentral zu sammeln. Dann könne wir die verschiedenen Tools gegen die selbe Datenbasis laufen lassen und testen welche Algorythmen die besten sind und die Daten zusammenführen
- Epidemic Calculator
- predictions mit lstm, dense oder whatever nn ihr mögt
- disease equations fitten
- quasi md simulationen mit ansteckung bei interaktionen
- ein dashboard bauen was als frontend dienen könnte
- Mit http://www.bitplan.com/index.php/SimpleGraph könnte aus den CSV eine Graph-Datenbank gemacht und anschliessend mit Geo-Daten usw. verknüpft werden, damit wir Datenformate bekommen, die wir besser nutzen können.
- Json und CSV wäre sinnvoll
- Prognosen bieten sich generell verschiedene Ansätze an: 1. Fit der Daten an epidemiologische Modelle 2. Vergleich der Daten mit anderen Ländern (Italien, Südkorea, China) 3. Abschätzung durch Veränderungen im aktuellen Datensatz
- Susceptible Pool wichtig, also die Bevölkerungszahl %of pop infected e.g. Diamond P=23.58% 0.02 % China, 0.12% Norway
- Gesamtarchitektur/Schnittstellen-Festlegung zwischen Daten, Modellierung und Visualisierung?
Vorgehensvorschlag
- Daten und Events (Maßnahmen) sammeln
- Modellierung, die daraus die Zukunft vorhersagen kann
- Visualisierung der Zukunft (ähnlich Wettervorhersage)
- Interaktive Visualisierung bei der sich einzelen Events abschalten lassen und die Folgen sichtbar sind (aus den Modellen abgeleitet)
Wie geht's weiter
Links
- https://paul-em.github.io/covid-19-curves/
- https://github.com/paul-em/covid-19-curves
- http://www.wiwi.uni-muenster.de/fbach/
- https://de.wikipedia.org/wiki/Coronavirus-Epidemie_2019/2020
- https://www.thelancet.com/journals/laninf/article/PIIS1473-3099(20)30120-1/fulltext
- https://github.com/CSSEGISandData/COVID-19
- https://www.ecdc.europa.eu/en/geographical-distribution-2019-ncov-cases
- Epidemic Calculator: http://gabgoh.github.io/COVID/index.html
- https://npgeo-corona-npgeo-de.hub.arcgis.com/datasets/917fc37a709542548cc3be077a786c17_0/data
- https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Fallzahlen.html
- https://de.wikipedia.org/wiki/COVID-19-Pandemie_in_Deutschland
- https://de.wikipedia.org/wiki/SIR-Modell
- https://www.dgepi.de/assets/Stellungnahmen/Stellungnahme2020Corona_DGEpi-20200319.pdf
- https://www.sueddeutsche.de/politik/coronavirus-niederlande-herdenimmunitaet-1.4850134
Germany
- https://interaktiv.tagesspiegel.de/lab/karte-sars-cov-2-in-deutschland-landkreise/
- https://www.tagesschau.de/inland/coronavirus-karte-deutschland-101.html
Copy of google Doc
see https://docs.google.com/document/d/1DMAisYOtO1RZU7OVzppxrlRGVhjzJNq3eRiKbNHKC-g/edit#
Challenge #1757
Titel Predict the Curve Flattening
Challenge ID 1757 Predict the Curve Flattening
Join DevPost
Kategorie Kommunikation & Informationsvermittlung an Bürger*innen
Daten: Wie können wir Daten besser aufbereiten und nutzen?
Task
Jeder redet von #flattenthecurve aber wie sieht die Kurve eigentlich aus und wie entwickelt sie sich? Ich habe in den letzten Tagen bereits eine Open-Source Visualisierung mit Daten der John Hopkins University gemacht: https://paul-em.github.io/covid-19-curves/ Spannend wäre allerdings zu wissen wie sich anhand des Momentums die Kurve entwickeln könnte und vielleicht noch andere Darstellungsformen zu entwickeln. Vielleicht wären hier Mathematiker ganz gut. Ich wäre als Informatiker jedenfalls dabei! Formulierung Herausforderung Wir können einfach darstellen ob die getroffenen Maßnahmen Wirkung zeigen.
Getting started
Du bist später dazu gekommen und magst helfen? Wir sind in subgruppen organisiert. Suche dir eine subgruppe aus und trete dieser auf Slack bei. Solltest du die Gruppe nicht auf Slack finden, dann haben sind die Leute immer noch nicht in eine öffentliche Gruppe umgezogen [ :( ]. Schreibe dann am besten die verantwortlichen Person und lass dich hinzufügen. Das weitere Vorgehen ist in den Subgruppen beschrieben
Ziele
- saubere und strukturierte Daten
- Datengrundlage in Deutschland
- Zeitreihen-Analyse
- Zusammenhang zwischen Eindämmungsmassnahmen und Zeitreihen-Daten
- Verzögerung durch Inkubationszeit berücksichtigen
- Vergleich mit Ländern in denen die Wirkung schon eingetreten ist: China, Korea, Taiwan, ...
- Mapping Region Bevölkerungszahl siehe https://github.com/paul-em/covid-19-curves/blob/master/assets/populations.js
- Anwendern die Angst und Ungewissheit über die zukünftige Entwicklung nehmen. Exponentiell hört sich für die einen schrecklich an, die anderen nehmen es nicht ernst. * Ein Satz wie "Im April brauchen wir 500.000 Krankenhausbetten" hilft es besser einzuordnen.
- Anwendern die Notwendigkeit und Effizienz von Maßnahmen der Regierung aufzuzeigen. Eine Ausgangssperre ist hart, aber wenn man zeigt, dass wir dann im April doch nur 100.000 Krankenhausbetten brauchen, wird es vielleicht akzeptiert. Fakt ist: Bisherige Tools sind unzureichend, was die Prognose für die Zukunft anbelangt. "Flattening the curve" ist für den Mathematiker cool, für viele andere Menschen unverständlich.
- Berücksichtigung verfügbarer Krankenhauskapazitäten e.g. https://link.springer.com/article/10.1007/s00134-012-2627-8
- Datenaktualität für die Zukunft sicherstellen
Vorgehen
Devpost Projekt anlegen ähnlich https://devpost.com/software/lake-covid
Kommunikation
Zoom: https://stanford.zoom.us/j/3845589503 Gruppen-Channels: siehe unten
Ideen
- Aufbauend auf diesem Open-Source Projekt könnte weitergearbeitet werden: https://paul-em.github.io/covid-19-curves/ Andere Ansätze gibts es bereits einige.
- Wäre es nicht sinnvoll ein datenbank cluster aufzusetzen um die Daten zentral zu sammeln. Dann könne wir die verschiedenen Tools gegen dieselbe Datenbasis laufen lassen und testen welche Algorithmen die besten sind und die Daten zusammenführen
- Epidemic Calculator
- predictions mit lstm, dense oder whatever nn ihr mögt
- disease equations fitten
- quasi md simulationen mit ansteckung bei interaktionen
- ein dashboard bauen was als frontend dienen könnte
- Mit http://www.bitplan.com/index.php/SimpleGraph könnte aus den CSV eine Graph-Datenbank gemacht und anschließend mit Geo-Daten usw. verknüpft werden, damit wir *Datenformate bekommen, die wir besser nutzen können.
Json und CSV wäre sinnvoll
- Prognosen bieten sich generell verschiedene Ansätze an: 1. Fit der Daten an epidemiologische Modelle 2. Vergleich der Daten mit anderen Ländern (Italien, Südkorea, China) 3. Abschätzung durch Veränderungen im aktuellen Datensatz
- Susceptible Pool wichtig, also die Bevölkerungszahl %of pop infected e.g. Diamond P=23.58% 0.02 % China, 0.12% Norway
- Gesamtarchitektur/Schnittstellen-Festlegung zwischen Daten, Modellierung und Visualisierung?
- In every group one member should be in charge of communicating with the other sub-groups, to ensure good communication between all groups.
Vorgehensvorschlag
- Daten und Events (Maßnahmen) sammeln
- Modellierung, die daraus die Zukunft vorhersagen kann
- Visualisierung der Zukunft (ähnlich Wettervorhersage)
- Interaktive Visualisierung bei der sich einzelne Events abschalten lassen und die Folgen sichtbar sind (aus den Modellen abgeleitet)
Workspaces
Organisation
Organisationsstruktur und Data Flow
Data Collection -> Data API -> Modeling <- Visualization Architecture Overview of Subgroups Responsible Sub-Group Slack Chat Name Paul Em Visualisierung
- challenge 1757 visualisierung
Tobias Hölzer Data API
- 1757_datensammlung
Elias Küpper <3 Architektur
- 1757_architektur
Tobias Hofmann Data Collection
- 1757_datensammlung
Vroni Bierbaum Modellierung
- 1757_modellierung
Architektur (DE)
- 1757_architektur
This group tries to create a common solution out of the parts developed by the other working groups: https://docs.google.com/document/d/1K1_plqtRlrpn2tjNohiEXPTrNDtBRq2F13HqvTA1-Lo/edit#
Communication Channel: #1757_architektur
Contact for Channel: Elias Küpper
Data Collection (DE)
The data collection group is collecting data on measures ordered by local or federal governments here:
https://docs.google.com/spreadsheets/d/1CW99DTTWFO5T3oiERzRaHGqpAQ_J-3PfwaMibUgJp4Y/edit#gid=262317549
An overview of available Data: https://docs.google.com/spreadsheets/d/13la9BFcPUeZKnx6amfwogzmhcNxtF_ouBiV6aOpDHFM/edit#gid=0
Communication Channel: # 1757_datensammlung Contact for Channel: Tobias Hofmann, Berit Zeller-Plumhoff Data Warehouse (DE) Problemstellung: Gesammelte Roh-Daten zu strukturieren und in einer NoSQL Datenbank (MongoDB) um diese strukturierten Daten nun mittels einer REST API zur Verfügung zu stellen.
Communication Channel: #challenge-1757-datawarehouse
Contact for Channel: Tobias Hölzer
Data Collection
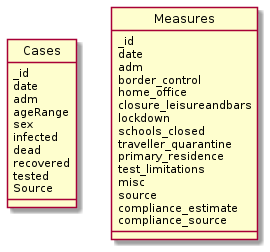
Visualization (DE + EN)
Wir, im Team Visualisierung, versuchen jetzt mal mit den bestehenden Daten einfach noch mehr insights zu den Kurvenverläufen zu generieren ohne aufwändige Berechnungen, gerne können wir hier auch Designer aufnehmen. Ich denke es macht sehr viel Sinn wenn es ein Team gibt, das sich spezialisiert darauf mit welchen Statistischen Berechnungen man hier noch den weiteren Verlauf berechnen kann und welche Daten dafür noch notwendig sind. Darauf aufbauend könnten wir dann im Team Datamodelling versuchen diese Daten zu bekommen, aggregieren und bereitzustellen
We are currently working on implementing first simple tools into the pre-existing visualization on https://paul-em.github.io/covid-19-curves/ to display and predict the total number of confirmed cases (currently only using oversimplified models :).
Use confirmed published data of “early” countries (China, South Korea, Italy) as a tool to compare confirmed cases with confirmed cases of “late” countries The infections started in some countries earlier than in others. The goal of this subproject is to take advantage of the published daily official data (confirmed cases, confirmed deaths, confirmed recoveries available in open databases such as JHU CSSE https://github.com/CSSEGISandData/COVID-19) to predict the development in countries with delayed outbreaks. We define the start of the outbreak as the first day, where the total number of confirmed cases exceeded a chosen threshold value (e.g. 200 confirmed cases). Countries with cases below this this threshold value are often capable of confining the outbreak. However, as soon as this threshold is reached, infections can often no longer be contained and the number of total cases increases exponentially (logistical growth). By comparing the data with “early” countries, the number of confirmed cases can be estimated for “late” countries.
How
Open questions & tasks:
Question: How to account for differences between countries? (population size, Case definitions, testing capabilities, community spread, number of infected clusters, … )
- How can we adjust the data/display the data in a useful manner to account for these differences?
- Maybe change subgroup name to “Predictive Data Visualization/Comparison/Forecast” or similar?
- Task: Create database containing country differences (ideally in csv format see JHU CSSE). Team database?
- Task: Display actions taken by each country, link to each data point in plot/display in plots? (e.g.: *country*, *date*, *action*; “Germany, 14/03/2020, Closing Schools”) Team database?
- Task Disclaimer: How does test capacity and case definition affect the graphs?
Status: First implementation of timeshifted plots completed, currently two team members
- Which features in the final product/prototype?
Disclaimer: What can be inferred from the displayed information? What can NOT be inferred? How can we communicate this uncertainty clearly? Sharing Views? Display the effect of taken actions (isolation, social distancing)
Tool to fit simple models (e.g. logistic growth) to the available published data without making any additional assumptions or simulations E.g. Inflection point analysis tool, logistic curve tool Goal: Roughly predict the curve flattening by fit to logistic function (when the growth of total number of confirmed cases is expected to slow down; see time series of total confirmed cases China, South Korea slowing down at around 80000, 8000 cases).
Status: Nobody actively working on this yet
Implementation of advanced models (data from modeling group)
Status: Nobody actively working on this yet. Waiting for data from modeling group.
Communication Channel: #challenge_1757_visualisierung
Contact for Channel: Paul Em (/ Paul Frml)
Modeling (DE)
General Communication Channel within modeling : #1757_modellierung
The Modeling group has organised themselves in further subgroups. The subgroups will use different methods to implement the models. The methods and subgroups are: Ordinary differential equations: https://wirvsvirus.slack.com/archives/C0103T4RPR8 Stochastic simulation: https://wirvsvirus.slack.com/archives/C0106K0PCM7 Machine Learning #1757_modellierung_ml Please join the slack channels, if you want to work in the group.
Github: (public) https://github.com/joshuakuepper/Challenge-1757
Subgruppe ODE:
Zoom-Meeting:
Wir haben uns dazu entschieden das SEIR Modell in Python zu implementieren. Dafür wird der Code auf Github geteilt: https://github.com/joshuakuepper/Challenge-1757/tree/master/deterministic_models
Die Parameter werden aus Veröffentlichungen von Instituten entnommen. Veröffentlichung des RKI zur Entnahme von Parametern: https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Modellierung_Deutschland.pdf?__blob=publicationFile Stellungnahme der Deutschen Gesellschaft für Epidemiologie zur Entnahme von Parametern: https://www.dgepi.de/assets/Stellungnahmen/Stellungnahme2020Corona_DGEpi-20200319.pdf
R0 könnte von der ML Gruppe als Zeitreihe je nach erforderlicher Maßnahme gegeben werden. Die anderen Parameter kommen aus den og Publikationen. Das Modell wurde etwas erweitert, die Modellparameter müssen aber irgendwoher kommen (ML Gruppe? Publikationen?)
Weitere relevante Links: Simulating COVID-19 interventions with R Pandemic Preparedness Planning for COVID-19: http://covidsim.eu/ Paper zum Modellierung: https://arxiv.org/pdf/2003.06031v1.pdf SEIR model + dashboard: https://neherlab.org/covid19/ SEIR model visualisierung:https://gabgoh.github.io/COVID/index.html Estimating actual COVID 19 cases (novel corona virus infections) in an area based on deaths: https://www.youtube.com/watch?v=mCa0JXEwDEk
Sub-gruppe Stochastic Model:
Zoom-Meeting: https://ethz.zoom.us/j/666255196
Start with basic stochastic SIR model: S + I -> 2*I with probability 0.025 I -> R Df N particles, each has a label (S/I/R) Each day, each particle chooses m (13.3?) other particles uniformly at random When a S and a I particle meet, w.p. p(=0.025?), the S particle becomes I Each particle has a exponential recovery distribution (median 5), when that time is up they become R Let S, I, R denote the number of each particles (so that N=S+I+R). We are only interested in contacts where one of the two particles is of type I and the other is S. In total, we have Nm collisions and the probability of one of them being S and the other I is SI/N^2. Further, for every contact, with probability p we have transmission. Therefore, the number of new infections (S->I) is distributed according to a Bin(Nm, S*I*p/N^2). Moreover, if we assume that the recovery time follows an exponential distribution, the probability of a patient having had the disease for k days recovering today is 1-e^(-L) where L is the parameter of the exponential distribution. (Gets more complicated for double exponential: will depend on k.) Thus, the number of recoveries (I->R) is Bin(I,1-e^(-L)). In summary: the numbers S, I, R follow a simple progression: each day S->S - A I-> I + A-B R-> R+B Where A, B are independent, A~Bin(Nm, S*I*p/N^2) and B~Bin(I,1-e^(-L)).
Extensions: Do this for several communities, add interaction term between each community Add an “exposed” group, assuming that once individuals show symptoms (i.e. they know they are I), they will seek fewer contacts Model different government intervention as reducing the average number of contacts m Parameter fitting? Relation to visualisation
Quantitative forecasts:
jangevaare/Pathogen.jl: Simulation, visualization, and inference tools for modelling the spread of infectious diseases with Julia
Modeling COVID-19 Spread vs Healthcare Capacity
coronafighter/coronaSEIR: Simple SEIR model Python script for the COVID-19 pandemic with real world data comparison.
Impact of non-pharmaceutical interventions (NPIs) to reduce COVID- 19 mortality and healthcare demand
http://gabgoh.github.io/COVID/index.html
Develop models for practical forecasts of cases of infections, ICU cases and deaths. Many possible approaches:
Model des
Statistical models Timeseries Arima - Schwer Anzuwenden Regression Death yes/no - logistische Regression (Logit-Modell) Bestimmte Anzahl an Erkrankten prognostizieren - “klassische” Regression parametric timing distributions (Poisson/Weibull) for infection: https://arxiv.org/pdf/1009.4362.pdf https://www.wiwi.uni-muenster.de/fbach/
Examples
- http://www.scholarpedia.org/article/State_space_model
- https://en.wikipedia.org/wiki/Error_correction_model
- https://github.com/sarahhbellum/NobBS
- https://towardsdatascience.com/modeling-exponential-growth-49a2b6f22e1f
SEIR
Groups: Susceptible, Infected, Exposed (affected, not spreading), Recovered… Deterministisch (DGLs) oder stochastisch https://gabgoh.github.io/COVID/index.html https://rviews.rstudio.com/2020/03/19/simulating-covid-19-interventions-with-r/ (EpiModel) Idea: Include detected and dead (reliable data available!), fit model parameters to known data, estimate real number of exposed We need to separate two subgroups: 1) parameter fitting and 2) simulation given a set of parameters Combination of network models and contagion models: https://arxiv.org/abs/1408.2701 Epidemiological models (calibrated). Interlinked Systems of SIR/SIS models (to add a spatial component for cities, counties etc.) https://arxiv.org/pdf/1701.03137.pdf Stochastic SIR/SIS models https://staff.math.su.se/hoehle/blog/2020/03/16/flatteningthecurve.html (https://rviews.rstudio.com/2020/03/19/simulating-covid-19-interventions-with-r/) (https://wirvsvirus.slack.com/files/U01049R3EUB/F0105VC5657/pan2014.pdf) / https://link.springer.com/article/10.1007/s11203-014-9091-8 https://github.com/CEIDatUGA/ncov-wuhan-stochastic-model More general Markov chain models on graphs to model more hypotheses (quarantines, border closures, social distancing…) The Imperial College model focus is on NPI, or predicting the virus spread as a function of different strategies, such as suppression of social contacts, or mitigation alone. The impact of the latter is a dramatic number of deaths, and some optimum strategies are developed that aggregate different containment measures in time. https://www.kaggle.com/c/covid19-global-forecasting-week-1/notebooks Machine Learning Methods NN / Gradient Boosting / Random Forest; also connectable with network model Zeitreihen per LSTM etc. https://www.wsj.com/articles/scientists-crunch-data-to-predict-how-many-people-will-get-coronavirus-11584479851 CBCV model: https://www.wiwi.uni-muenster.de/fbach/
Tools (dedicated statistical software packages): (add short descriptions?) Package 'bsts'
- https://cran.r-project.org/web/packages/dlm/dlm.pdf
- https://www.statsmodels.org/stable/index.html
- https://www.gnu.org/software/octave/
R0 package (estimation of basic reproduction rate), article: https://www.ncbi.nlm.nih.gov/pubmed/23249562
Illustrative / qualitative models:
Network models (e.g. SIR on graph)
Qualitative epidemiological models
Graph theory : firefighters
Tools (dedicated illustrative models):
Network models:
More info: https://github.com/patrickfrank1/covid-19-project164
Communication Channel: #1757_modellierung Contact for Channel: Vroni Bierbaum
Simulationen
- http://covidsim.eu/
- Epidemic Calculator: http://gabgoh.github.io/COVID/index.html
- Source code: https://github.com/gabgoh/epcalc
- https://web.br.de/interaktiv/corona-simulation/
- https://covid19visualiser.com/
Datensätze / Links
- EuropeanDataPortal Datensätze zur Weltweiten Corona-Ausbreitung
- Personal in Krankenhäusern in Deutschland (1991-2017)
- Mautdaten Bund - Indikator für kurzfristige Entwicklungen der wirtschaftlichen Situation
- RKI Daten Bundesländer
- RKI Daten Landkreise
- Johns Hopkins CSSE (.csv)
- Johns Hopkins CSSE Daten (REST-API)
- EU-Open Data-Portal (.csv)
- Euromomo - Mortality Monitoring EU
Feed of hostnames found in certificate transparency logs that are related to the COVID-19 pandemic (.csv): https://1984.sh/covid19-domains-feed.txt
Kaggle: Daily Cases of Corona (.csv)
https://www.kaggle.com/sudalairajkumar/novel-corona-virus-2019-dataset
Corona Cases Schweiz (.csv)
https://github.com/daenuprobst/covid19-cases-switzerland
GovData
https://www.govdata.de/
COVID-19 / SARS-CoV-2 resources
https://gehrcke.de/2020/03/covid-19-sars-cov-2-resources/
Point of Interest Daten
www.algoly.com
Alle POI-Daten verfügbar mittels einfacher API oder self publishing in Excel. Abrufbar auf Adresse genau oder großem Radius. Algoly übernimmt bei #WirvsVirus Projekten die Serverkosten und können viele Daten kostenfrei oder zum EK-Preis zur Verfügung stellen. Schicke einfach dirk@algoly.com eine mail
Demografische & Soziografische Daten
www.algoly.com
Demografische und Soziografische-Daten (Einkommensstruktur, Alter, Bildung, etc.) verfügbar mittels einfacher API oder self publishing ins
Excel. Abrufbar auf Adresse genau oder großem Radius. Algoly übernimmt bei #WirvsVirus Projekten die Serverkosten und können viele Daten
kostenfrei oder zum EK-Preis zur Verfügung stellen. Schicke einfach dirk@algoly.com eine mail
COVID-19 image data collection
https://github.com/ieee8023/covid-chestxray-dataset
JSON mit gemeldeten CORONA Fällen auf Landkreis
https://services7.arcgis.com/mOBPykOjAyBO2ZKk/arcgis/rest/services/RKI_COVID19/FeatureServer/0/query?where=1%3D1&outFields=*&outSR=4326&f=json
Achtung! Nur die ersten 2000 Datensätze. Für mehr muss paging verwendet werden!
Coronavirus Disease (COVID-19) – Statistics and Research
https://ourworldindata.org/coronavirus
XAPIX Service Endpoints für verschiedene COVID-19 Daten
https://www.xapix.io/covid-19-initiative
Covid19API (stabile API mit versch Endpunkten basierend auf John Hopkins Daten), Krankenhausbetten (leider nur Californien), point of interest Daten
Übersicht in Deutschland
https://www.citypopulation.de/de/germany/covid/
Aufteilung nach Bundeländern
Mobilitätsdaten Portale
https://gobeta.de/projekte/dataportale/
Manuelle Liste DE nach Landkreisen
https://docs.google.com/spreadsheets/d/1wg-s4_Lz2Stil6spQEYFdZaBEp8nWW26gVyfHqvcl8s/htmlview#
Kaggle Forecast Dataset Sharing
https://www.kaggle.com/c/covid19-global-forecasting-week-1/discussion/137078
- https://paul-em.github.io/covid-19-curves/
- https://github.com/paul-em/covid-19-curves
- http://www.wiwi.uni-muenster.de/fbach/
- https://de.wikipedia.org/wiki/Coronavirus-Epidemie_2019/2020
- https://www.thelancet.com/journals/laninf/article/PIIS1473-3099(20)30120-1/fulltext
- https://github.com/CSSEGISandData/COVID-19
- https://www.ecdc.europa.eu/en/geographical-distribution-2019-ncov-cases
- https://npgeo-corona-npgeo-de.hub.arcgis.com/datasets/917fc37a709542548cc3be077a786c17_0/data
- https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Fallzahlen.html
- https://de.wikipedia.org/wiki/COVID-19-Pandemie_in_Deutschland
- https://de.wikipedia.org/wiki/SIR-Modell
- https://www.dgepi.de/assets/Stellungnahmen/Stellungnahme2020Corona_DGEpi-20200319.pdf
- https://www.sueddeutsche.de/politik/coronavirus-niederlande-herdenimmunitaet-1.4850134
- https://interaktiv.tagesspiegel.de/lab/karte-sars-cov-2-in-deutschland-landkreise/
- https://www.tagesschau.de/inland/coronavirus-karte-deutschland-101.html
- https://www.washingtonpost.com/graphics/2020/world/corona-simulator/
- https://www.spiegel.de/wissenschaft/medizin/corona-krise-lockdown-koennte-bis-ins-naechste-jahr-dauern-a-ea2e318b-b388-4ccc-8493-318f892381b8
- https://blog.datawrapper.de/coronaviruscharts/
- https://ourworldindata.org/coronavirus#growth-country-by-country-view
- https://neherlab.org/covid19/
- https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Modellierung_Deutschland.pdf
- http://shinyapps.org/apps/corona/
- https://chschoenenberger.shinyapps.io/covid19_dashboard/
Other challenges which might be helpful
0284 (Dunkelziffer schätzen) 0982 (Dunkelziffer radar) 0361 (Wie schaffen wir es eine realistische Schätzung von Zahlen für Infizierte zu bekommen und wie schaffen wir es neue Infektionsherde zu finden?)
- herausforderung 0999 (Übersicht über Zahlen und Kurven der aktuellen weltweiten Situation mit Extrapolation in die Zukunft)
- https://devpost.com/software/lake-covid
- https://devpost.com/software/038_daten_infektionszahlenschatzen
044 Flattenthecurve Optimize the curve